Building a Compounding CTI Knowledge Base
Disclaimer: The PRD, the implementation of this project, and this blog post were all AI-assisted. The ideas, requirements, and analytical standards are mine. AI helped me build and write faster.
Everyone is building personal AI knowledge bases right now. Karpathy published his LLM Wiki concept in early April, and the idea clicked for me immediately. Not for general knowledge, though. For CTI.
Most of my work involves taking fragmented context (actor intent, geopolitical signals, policy shifts) and turning it into a coherent picture. That is the problem this project solves.
If you do threat intelligence, you know the pain. You read a Mandiant report on Tuesday, a CISA advisory on Thursday, an OSINT thread on Friday. Each one adds a piece. But the picture lives in your head, fades over time, and three months later you are rebuilding it from scratch when someone asks "which actors target our sector?"
I have had this happen during threat reviews where I knew I read something relevant but could not find it or remember the detail.
Traditional RAG does not fix this, I've tried it before. It pulls chunks from scratch on every query with no awareness that the picture changed since last time.
I wanted something different.
Synthesize at ingest, not at query time
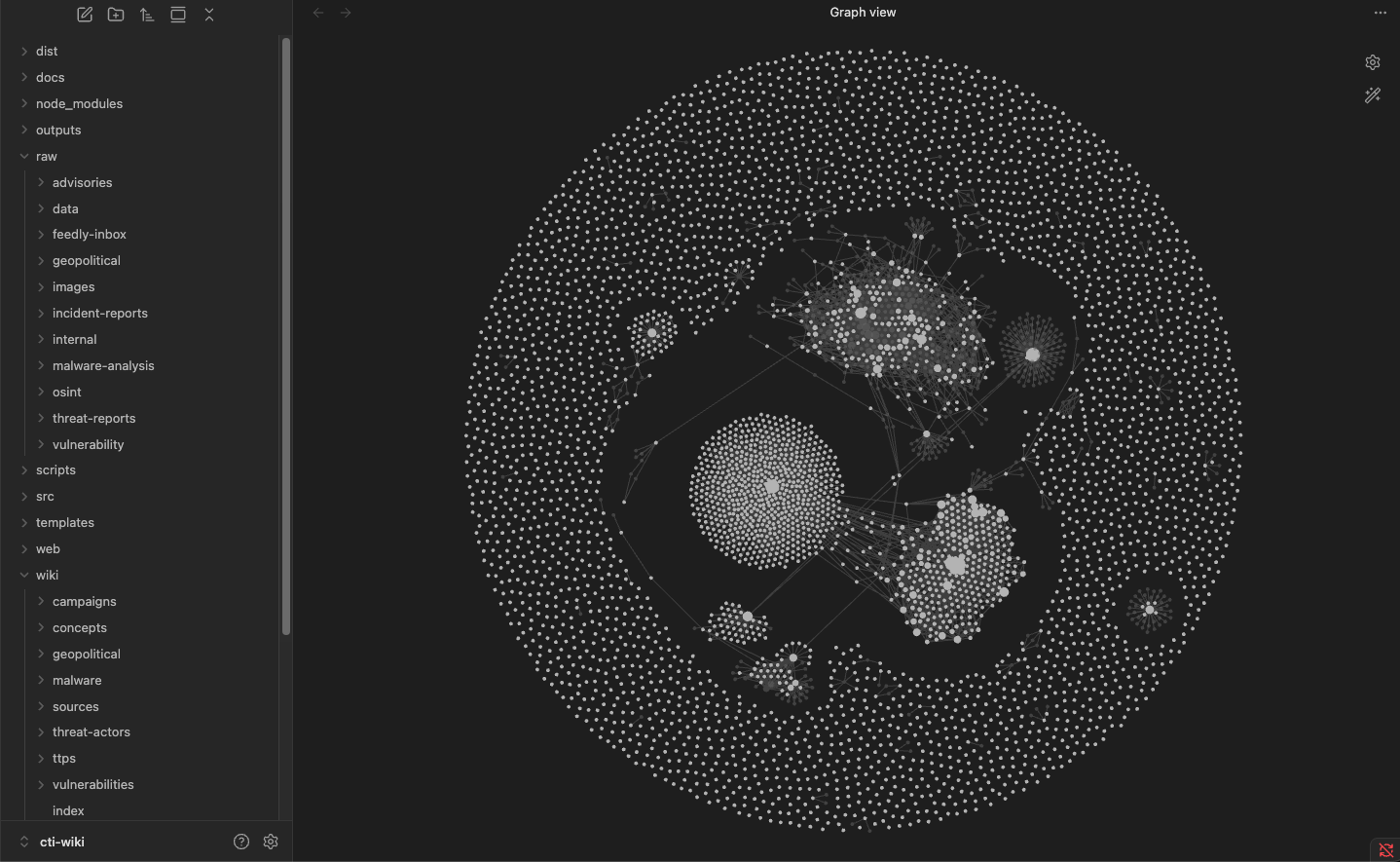
When a new source comes in, the system reads it, extracts the intelligence (actors, TTPs, campaigns, vulnerabilities, geopolitical context), and writes it into a structured wiki. If APT41 already has a page, that page gets updated. New campaign? It gets its own page, cross-referenced to actors, malware, and TTPs.
Pages live under wiki/, organized by type. A master catalog at wiki/index.md tracks every page, and wiki/log.md logs what changed and when.
One threat report usually touches 2 to 5 wiki pages. A single Mandiant APT update might "fan out" and hit the threat actor page, several TTP pages, a malware page, a campaign page, a source summary, and a geopolitical context page.
By the time you need to ask a question, the wiki already has the answer compiled and linked. No LLM is stitching chunks together on the fly. The picture is already there.
Why this matters
The picture compounds
Every report makes the wiki richer. Actor pages accumulate TTPs across sources. Campaign pages link to malware, sectors, and vulnerabilities. Geopolitical pages add strategic context. Over time you stop maintaining a pile of reports and start maintaining a threat landscape.
Contradictions surface
Sources disagree on attribution, timelines, and capabilities. Normal notes just overwrite the old take. This system keeps competing hypotheses visible. If Vendor A says MSS-affiliated and Vendor B says contractor nexus, both sit on the same page with confidence levels and citations. At the schema level, pages carry a competing_hypotheses field for exactly this.
Geopolitical context links to technical context
Export controls get announced. Six months later, targeting spikes from a specific actor cluster. Those signals usually live in a separate reading pile. In the wiki, geopolitical pages link directly to the actors and campaigns they explain. Pull up Volt Typhoon and you see the cross-strait context next to the TTP mappings.
Design choices
Source grading is mandatory
Every source gets a NATO Admiralty grade. A CISA advisory with vendor confirmation is an A1. An anonymous forum post is a D4. These grades live on source-summary pages under wiki/sources/.

ICD 203 confidence language
Attribution is never stated as fact. Always "assessed with high/moderate/low confidence." Enforced through schema.md, which loads into the LLM system prompt on every call.
Assessments get filed back in
Query the wiki, get a useful assessment, file it as a page under wiki/assessments/. It becomes a citable artifact that future queries can build on. Analytical work compounds like ingested sources do.
ATT&CK is built in
Every TTP carries its ATT&CK ID. Actor pages show technique coverage across kill chain phases. It is how the system organizes adversary behavior.
How this differs from Karpathy's original
The original LLM Wiki is for slow-paced personal reading. Maybe a few links a day. I am pushing large volumes of threat reports and news through this, trying to understand the current landscape and how it got here.
The goal is pattern recognition: see how actors behaved historically, what conditions preceded past campaigns, which TTPs cluster together, and you start building a basis for thinking about what comes next. The goal is to turn this wiki into an analytical workbench.
The PRD and technical architecture
I used Claude to help design the PRD. Useful for iterating on structure, testing the data model, and working through edge cases like conflicting attribution from two sources on the same campaign.
Three-layer directory structure. raw/ holds immutable sources (drop files in, never modify). wiki/ holds LLM-authored Markdown pages (the compiled intelligence). outputs/ holds query responses and briefings.
Wiki pages are organized by type: threat actors, campaigns, malware, TTPs, vulnerabilities, infrastructure, geopolitical context, sectors, and concepts. A threat actor page carries aliases, attribution with confidence, competing hypotheses, motivation, targets, TTPs, malware, and campaigns. Everything is cross-referenced with [[wikilinks]].
Three core operations.
- Ingest — Read source, extract entities, create or update wiki pages, assign source grade, add cross-references, log activity.
- Query — Read index, pull relevant pages, synthesize assessment with confidence language and citations.
- Lint — Check for attribution conflicts, stale intel, orphan pages, ATT&CK gaps, Diamond Model completeness, frontmatter validation.
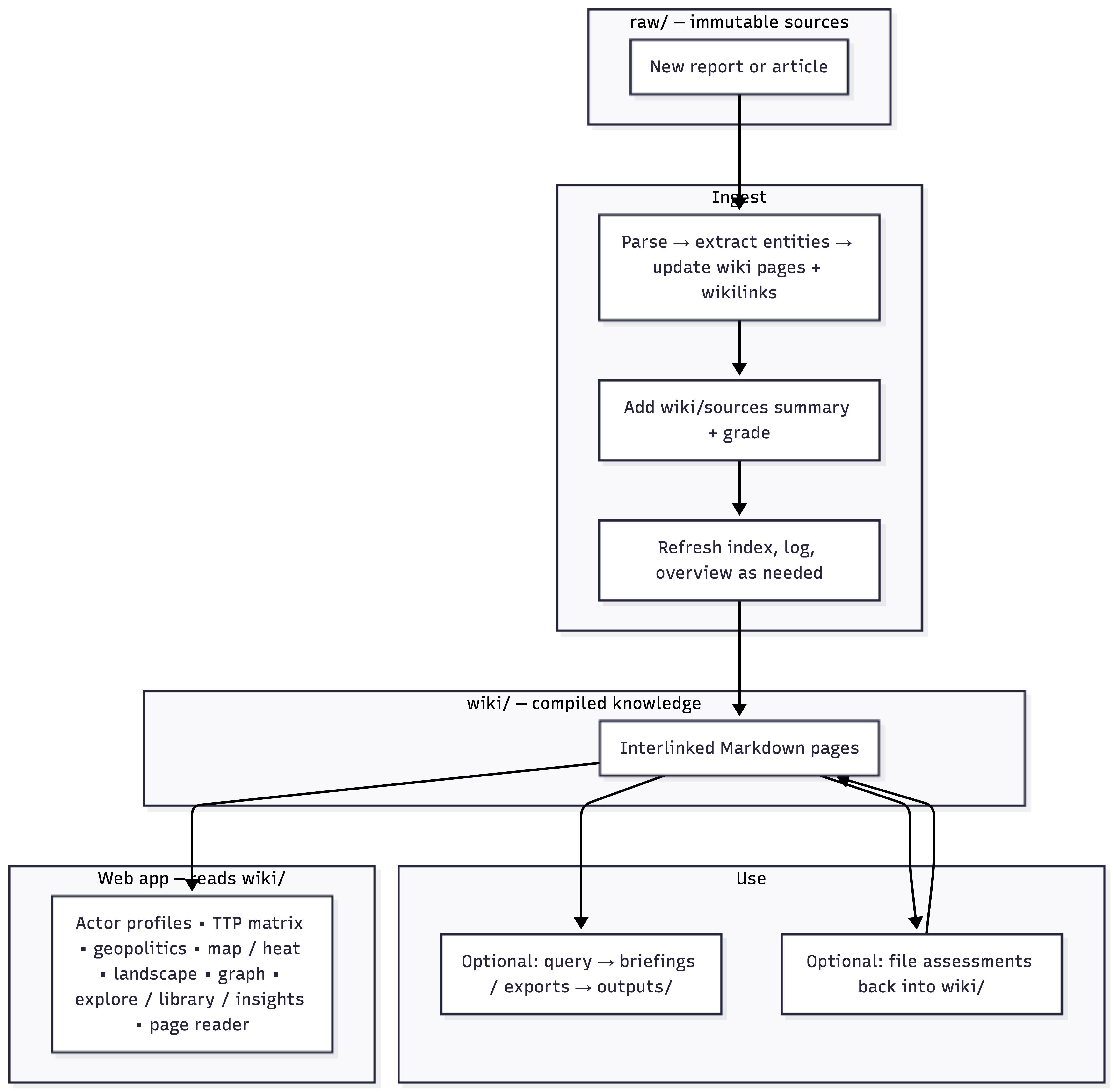
raw/, gets parsed and extracted into wiki pages with cross-references and source grading, then the compiled wiki feeds the web app, query engine, and assessment loop.In practice, I have been using Claude Cowork as the LLM layer instead of wiring up API calls. The ingest and cross-referencing logic works, but the full CLI pipeline is still being tested. It works as a workflow today, not yet as a finished tool.
Next milestone: API-driven ingest and better PDF extraction for image-heavy slide exports.
What this replaces (and what it does not)
This does not replace a TIP, which handles IOC management and sharing. This wiki handles narrative intelligence, relationship tracking, and analytical memory. They are complementary.
Ingest errors can also propagate across pages, which is why analyst review of new pages matters as much as review of query outputs.
THIS TOOL DOES NOT REPLACE HUMAN ANALYSIS. I use LLMs daily and I know how they hallucinate. The schema, source grading, and confidence language are there to push the LLM toward proper analytical discipline, but ultimately everything this system produces needs analyst validation. The LLM handles compilation. The tradecraft, and the responsibility for what gets briefed, stays with the analyst.
Where things stand
Still testing against my day-to-day work. Cross-referencing works, assessments come out with proper confidence language, and the lint system catches attribution conflicts and coverage gaps.
One early win: lint flagged an actor page where two sources gave conflicting campaign timelines, which I would have missed in my normal workflow. I won't be showing them here as both were from reputable vendors.
Some things I built because I could
On building your own projects.
Pros: you can build whatever you want.
Cons: you can build whatever you want.
I am not going to pretend everything AI touches turns to gold. But once you have a structured wiki with typed pages and wikilink relationships, you can generate views on top of it.
Cool? I think so.
Useful? Question for another time.
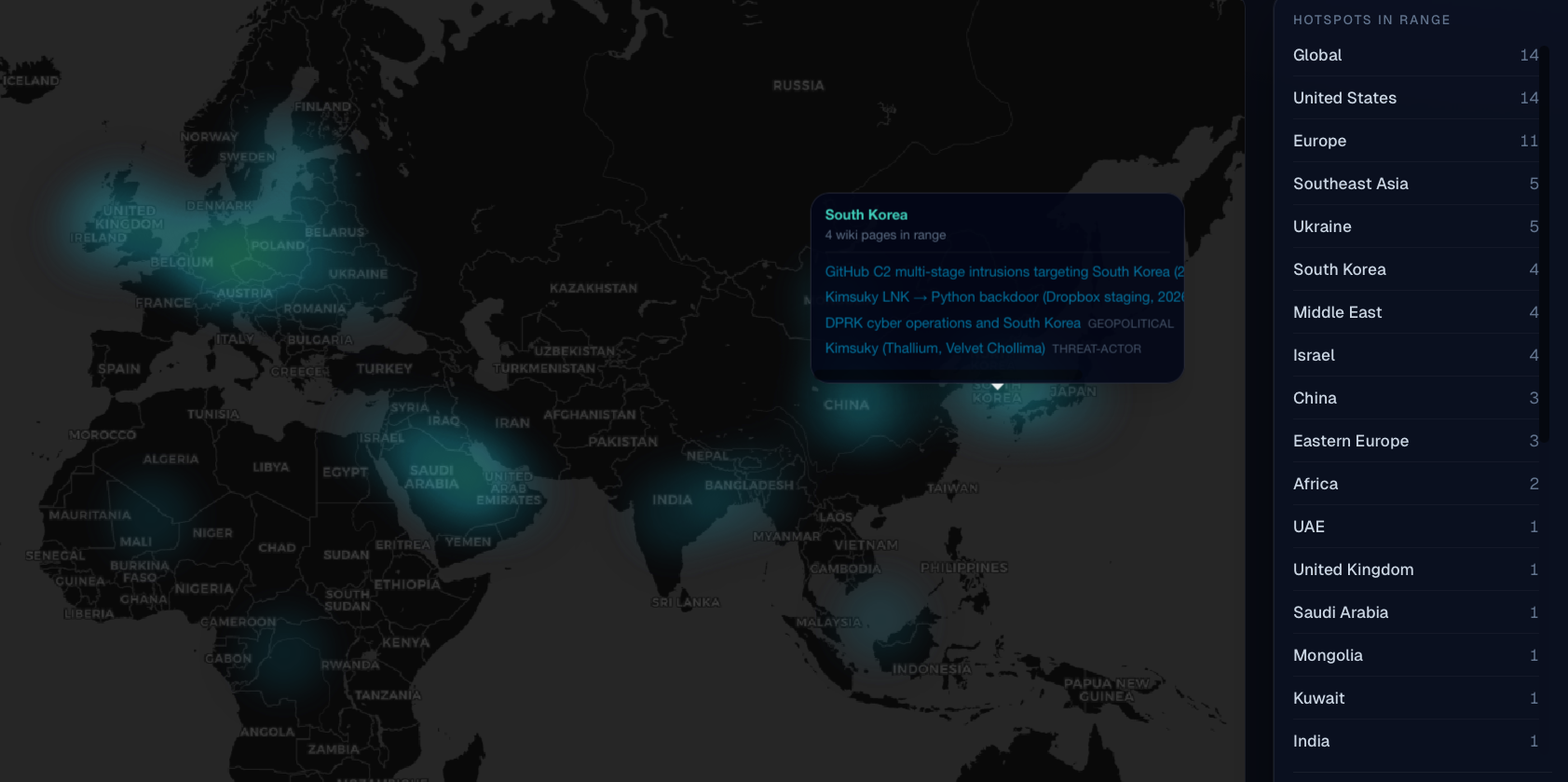
Geopolitical heatmap
Knowledge graph
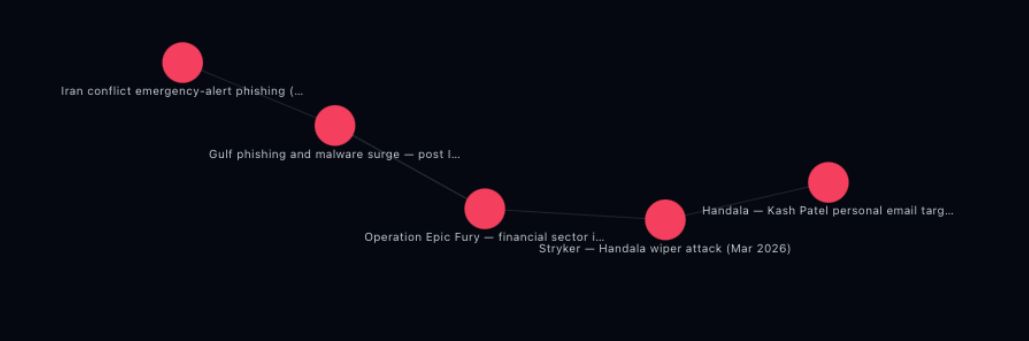
[[wikilinks]], colored by type. Good for spotting hubs, orphans, and natural clusters.Insights dashboard
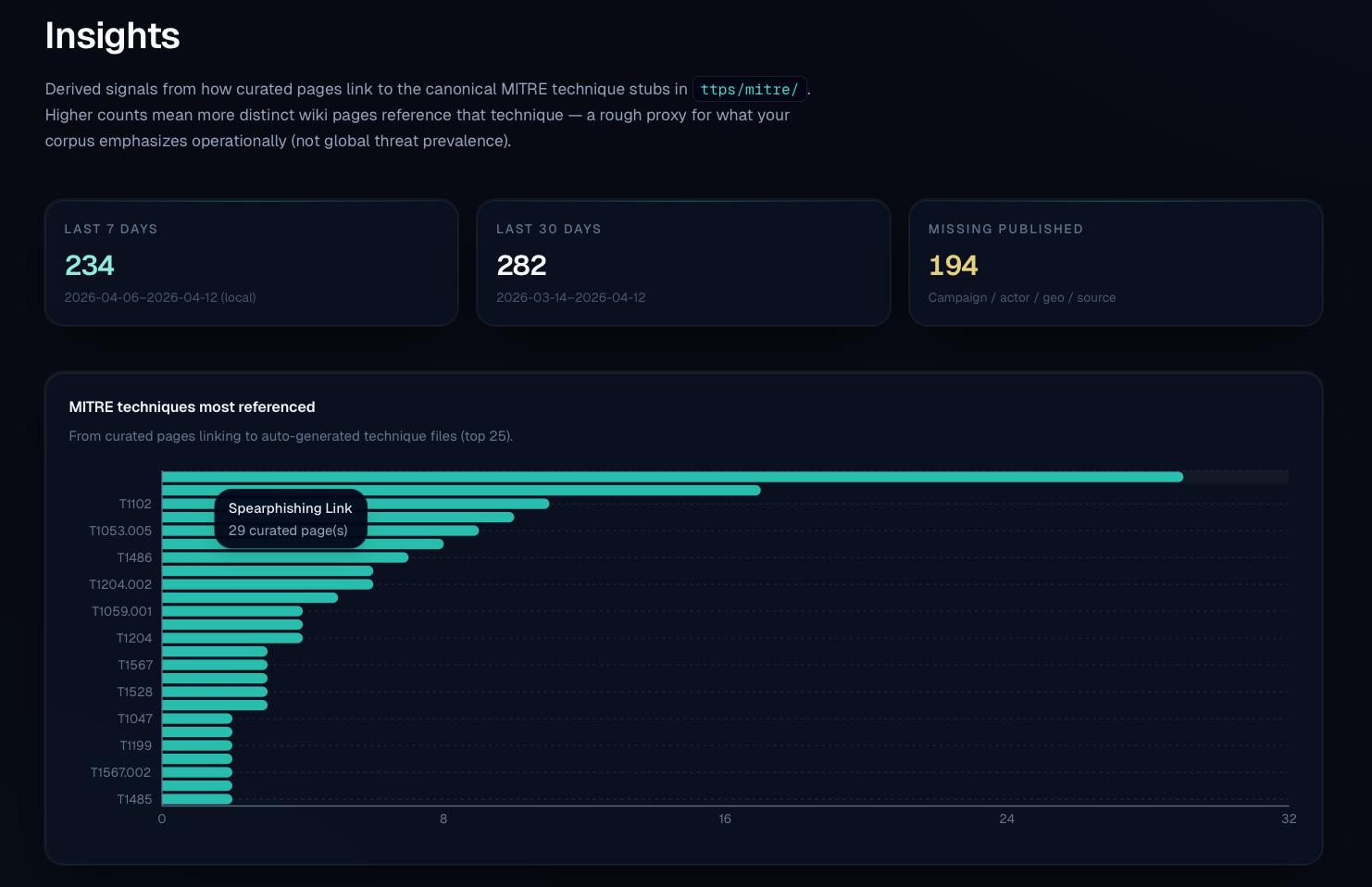
Where this could go
Right now ingest is semi-automated but not reliable enough to talk about in detail yet. The direction is clear though: point this at a stream of news articles, threat reports, advisories, and OSINT feeds, and the wiki stays current without the analyst starting every ingest.
That changes what this is. With automated ingest, it could start to function as an operational and strategic intelligence layer. Most TIPs handle technical intelligence like IOCs and signatures. The narrative side (who is doing what, why, what changed, what might come next) usually lives in analyst heads and slide decks. A continuously fed wiki that compiles narrative context could sit alongside the TIP and fill that gap. Technical intelligence tells you what happened. This helps you think about what it means.
I am not there yet. Automated ingest brings problems: source filtering, hallucination and LLM rate limits.
Closing thoughts
This started as a weekend project and turned into something potentially useful.
The core idea: compile intelligence at ingest time so the knowledge base gets smarter with every report, not just bigger. Bake analytical standards into the schema so the LLM cannot skip them. Cross-reference everything so context is one link away.
Not finished. Not polished. But every source I ingest makes the next query better. That compounding is the whole point.
